GPT-SoVITS声音克隆

GPT-SoVITS软件下载
打开路径https://github.com/RVC-Boss/GPT-SoVITS
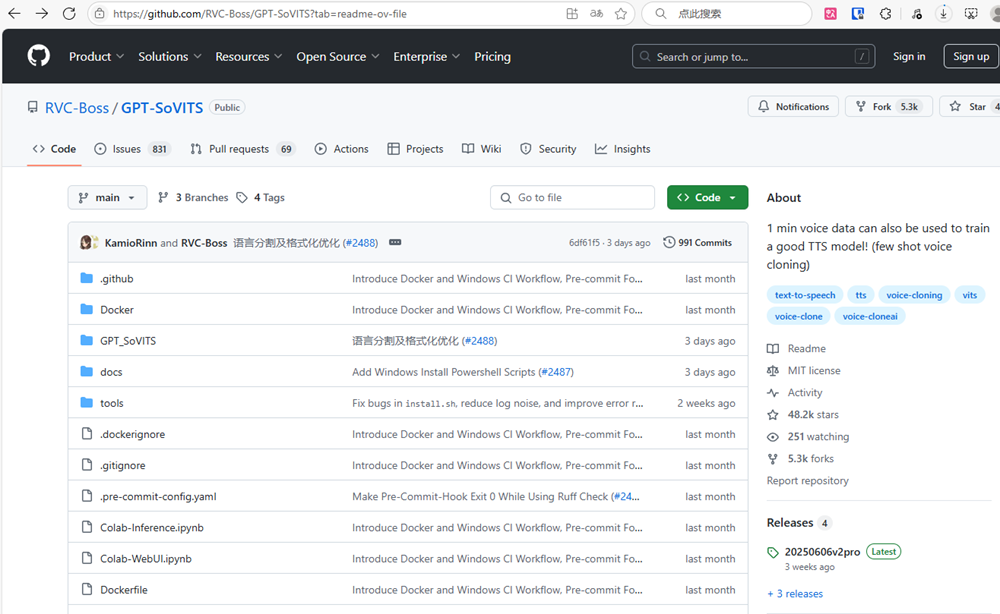
向下找到Windows部分,有"download the package here"字样;进入后下载整合包

下载解压后放在纯英文的目录下逐个打开子文件夹,找到go-webui.bat批处理文件;
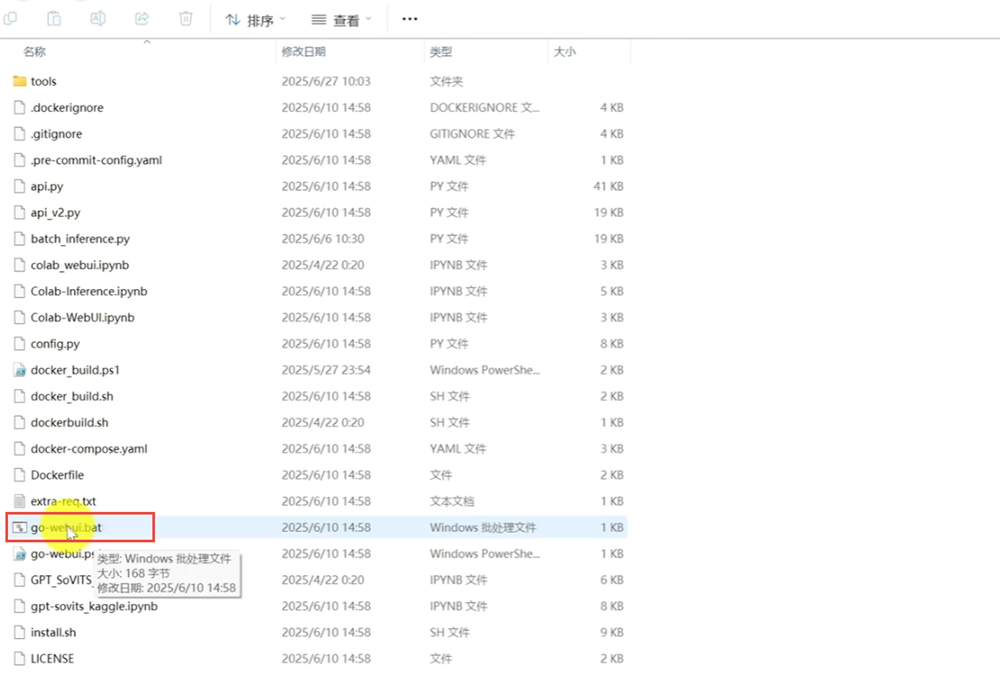
它会以浏览器的方式打开操作web页面;
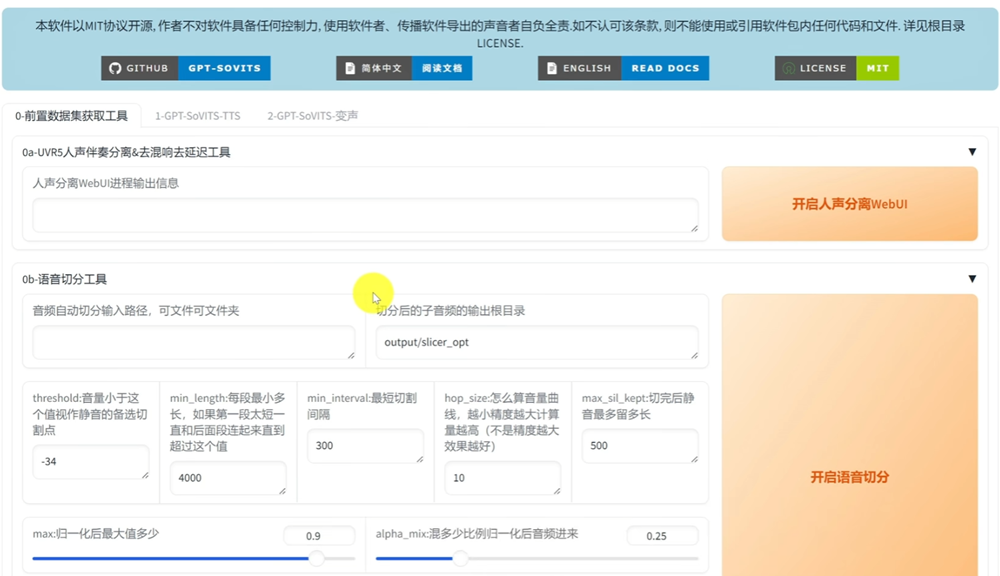
如何训练自己的模型
- 如果有现有的声音片段,可以利"开启人声分离WebUI"将背景音和噪杂的的声音分离出来。
- 如果需要分离的声音元素比较简单,可以选择HP2-all_vocals;
- 如果需要分离的声音元素比较复杂,它只会提取主要人声,尽可能的忽略或过滤掉其它声音,可以选择HP5-only_main_vocal;
- model_bs_roformer_ep_317_sdr_12.9755这个模型分离出来的音频质量非常高,但是计算量大,速度会慢一些;
- 下面的则是云回声、混响这些;
注:可以先用model_bs_roformer_ep_317_sdr_12.9755这个模型处理一遍,把人声提取出来。然后再用onnx—dereverb_By_FoxJoy这个模型做第二遍处理。最后用VR_DeEchoAggressive去混响,效果会更好。

声音分离操作完成后点击"关闭人声分离WebUI"节省缓存;

拿到纯净的声音后,我们还需要把它切成一个个10秒内的短句,输入音频自动切分输入路径,然后点"开启语音切分"就可以了。
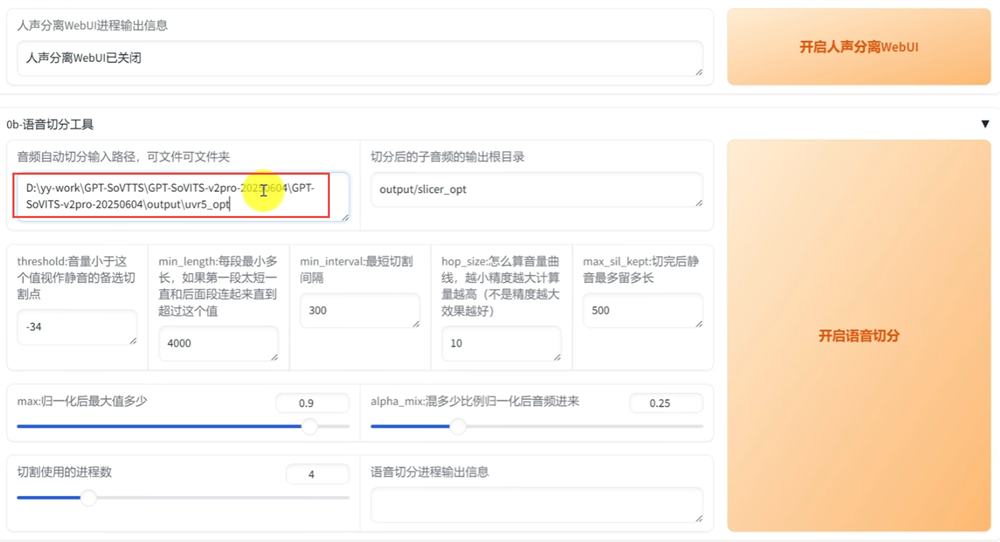
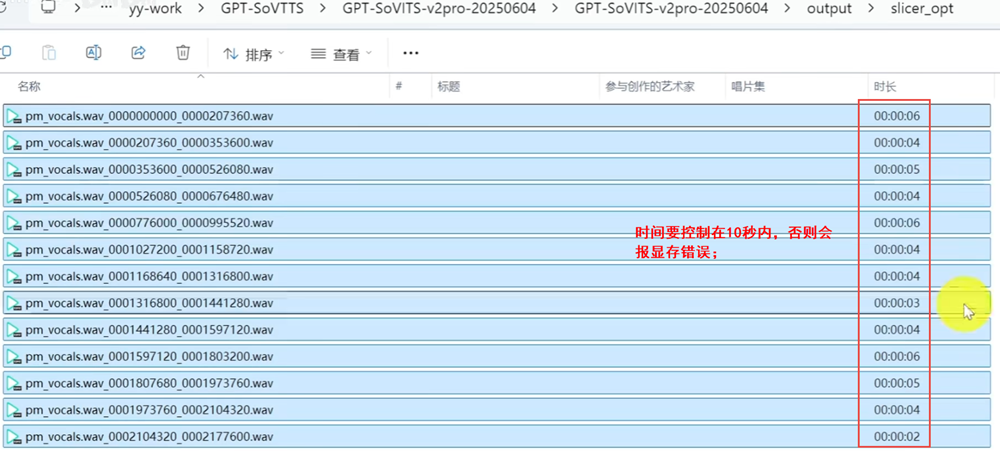
打开切分后的输出目录,每一个语音片段时间要控制在10秒内,否则会报显存错误。
开启语音识别就是把语音转成文本,将上一步切分的10秒内的语音转成文本。

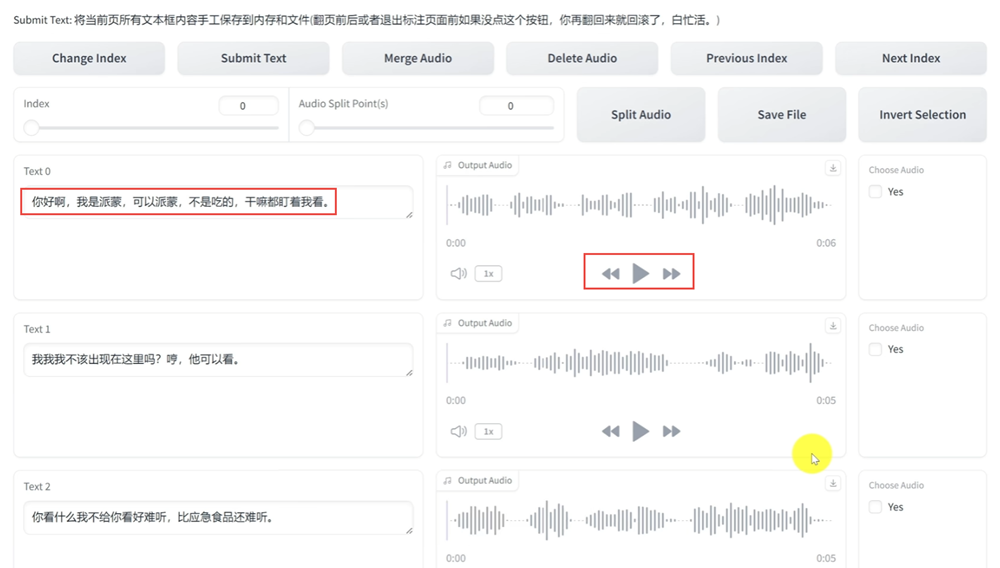
如果生成的语音文本不够准确,还需要对每一段音频对应的文字是什么进行打标,输入上一步生成的文本路径,点击开始音频标注WebUI;

此时会打开一个新的web页面,点击播放语音与左侧的文本对比,如果有错误的地方将其修改;保证播放的语音与文本一致;修改完以后点一下submit Text提交后才能点击下一页Next Index;直到全部标注完成,此时就可以点击"关闭音频标注"按钮了。【这一步很关键,直接关系到克隆的声音是否清晰】
前期工作都完成后就可以训练模型了。
点击"GPT-SoVITS-TTS"输入一个自己的模型名,选择一个模型的版本;

然后点击"开启训练集格式化一键三连"就可以了。

正式训练模型
点击"微调训练"需要进行SoVITS和GPT训练;训练完SoVITS后再训练GPT。【中配显卡1分钟的音频大概需要1~2分钟】

训练好的模型怎样使用
点击微调训练旁边的1C推理,选择训练好的GPT和SoVITS模型,点击开启TTS推理WebUI界面;
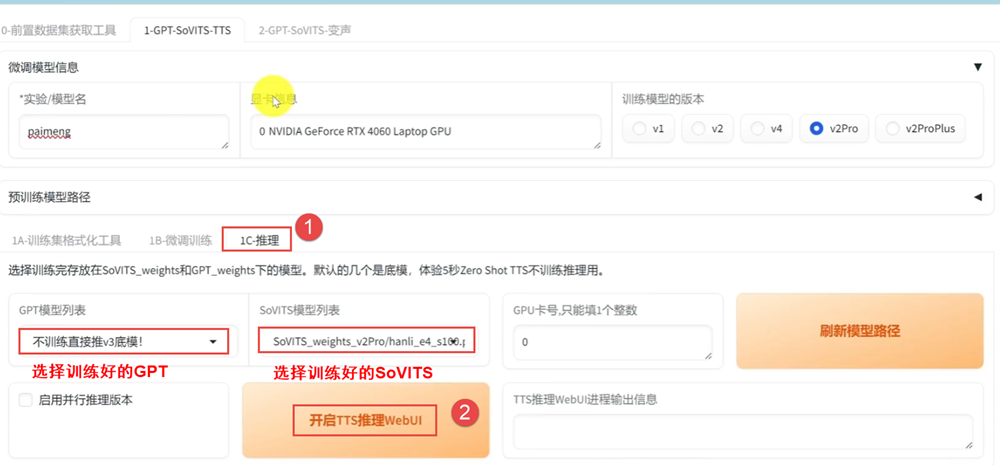
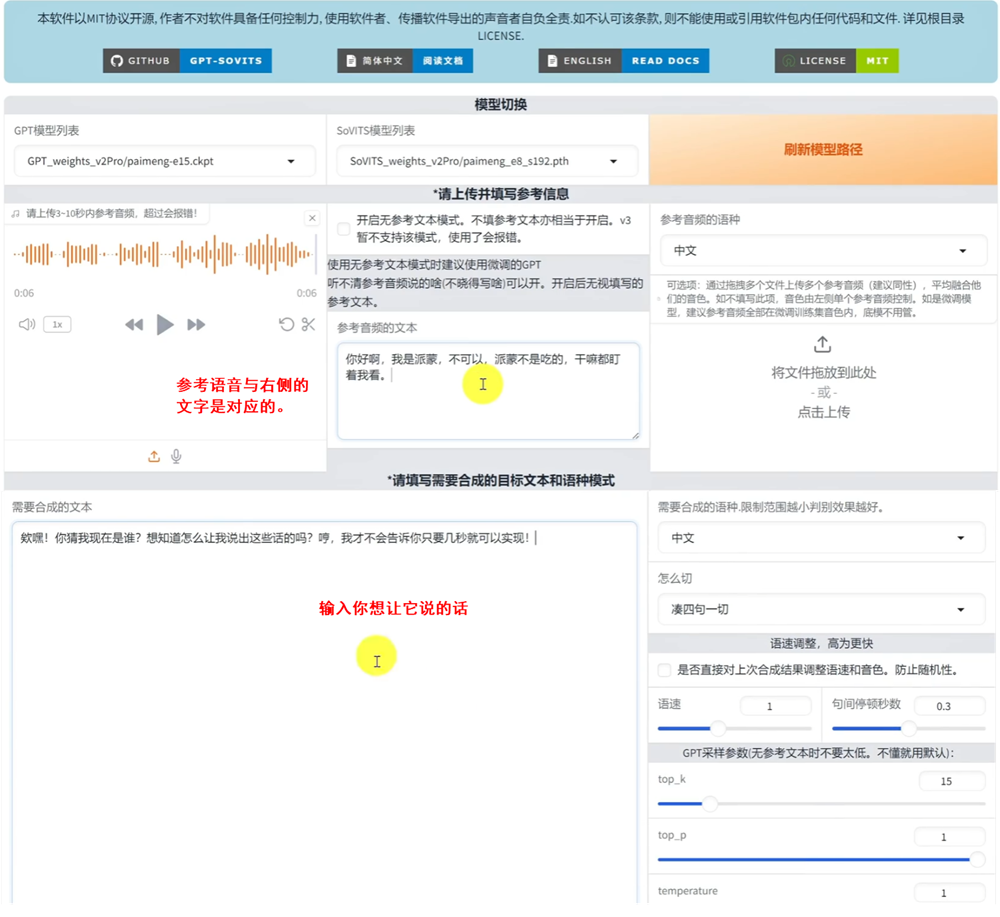
上传一段参考音频,它能让你的AI模仿这段参考音频的情感,语速和语调。上传参考语音以及参考语音对应的文本信息;再输入你想要说的话,点击合成语音。