
PyTorch深度学习

PyTorch加载数据
1、数据【垃圾是混乱的】
2、Dataset:可以把可回收的垃圾回收,并形成一个编号,每个数据所对应的一个lable,提供一种方式去获取数据和对应的lable值;
- 如何获取每一个数据及其lable
- 告诉我们总共有多少的数据
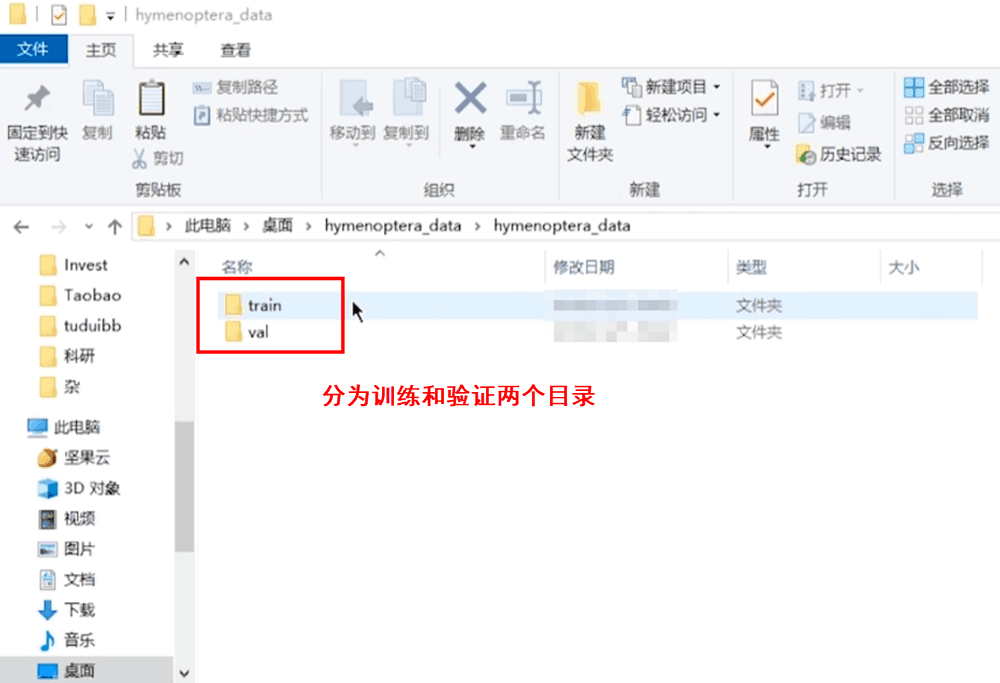
#在windows中的路径需要进行转义
img_path="K:\\pycharm_test\\dataset\\train\\000.png"
#引用头文件
import os
#是相对内容路径,也可用上面的绝对路径,需要转义
dir_path = "dataset/train"
Dataset实现代码:
#从torch常用工具中的数据区引入Dataset
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(root_dir,label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx): #支持获取给定密钥的数据样本
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label =self.label_dir
return img,label
def __len__(self): #将返回数据集的大小
return len(self.img_path)
root_dir = "dataset/train"
part1_label_dir = "part1"
part2_label_dir = "part2"
part1_dataset = MyData(root_dir, part1_label_dir)
part2_dataset = MyData(root_dir, part2_label_dir)
# 整个训练集就是第一个和第二个数据集的合,可以对数据集拼接,好处是可以加自己的图片时行训练
train_dataset = part1_dataset + part2_dataset
# 查看合并后训练集的长度
len(train_dataset)
img, lable = train_dataset[360]
img.show()
3、Dataload:对可回收的垃圾进行一个打包,为后面的网络提供一种不同的数据形式。
Tensorboard的使用
安装tensorboard模块
pip install tensorboard
运行后会生成测试代码
from torch.utils.tensorboard import SummaryWriter
# 生成一个logs事件
writer = SummaryWriter("logs")
for i in range(100):
writer.add_scalar("y=x",i,i)
writer.close()
在会生成一个logs事件文件夹,在命令行中运行
(unet) PS K:\code\pytorch_tb> tensorboard.exe --logdir=logs
生成代码
TensorBoard 2.19.0 at http://localhost:6006/ (Press CTRL+C to quit)
可以在运行的时修改端口
(unet) PS K:\code\pytorch_tb> tensorboard.exe --logdir=logs --port=6008
运行cmd命令后会生成图像。

transforms结构及用法
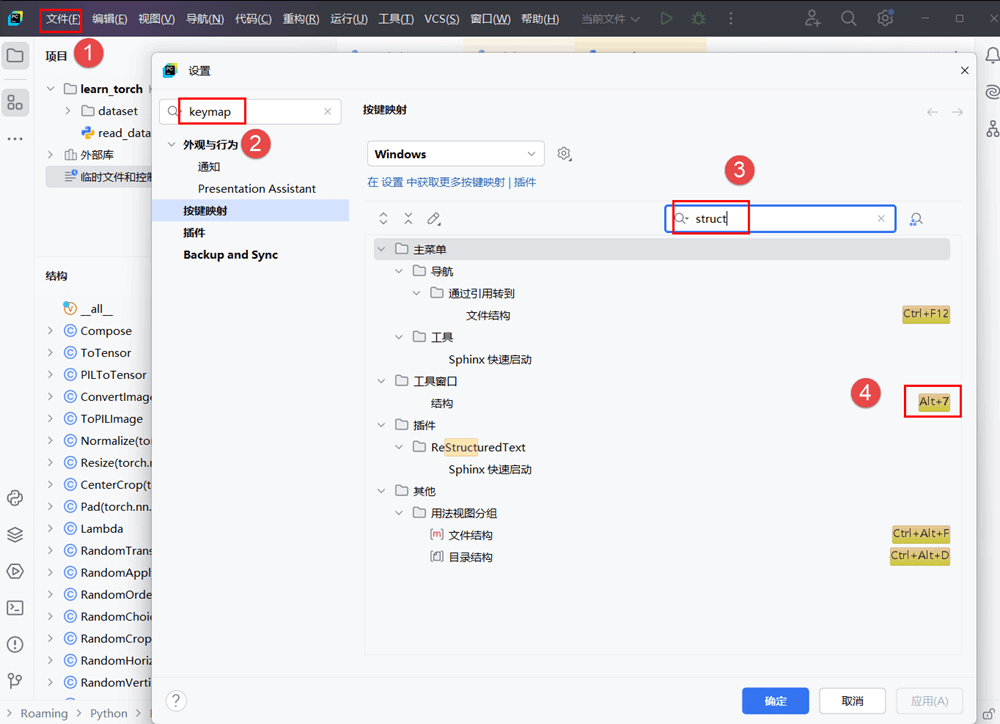
为了阅读代码方便,有进Pycharm编译器左边栏不出现"结构栏",此时可以在文件—设置——keymap ——-struct——按快捷键Alt+7即可。
引用库
image是python中内置的一个打开的库,从图标也可以看出。指向Image右击导入名称,选择库即可。

totensor工作示意图

功能实现代码:
from PIL import Image
from torchvision import transforms
# 相对路径
img_path = "dataset/train/ants_image/0013035.jpg"
img = Image.open(img_path)
# 使用transforms中的ToTensor函数生成一个工具
tensor_trans = transforms.ToTensor();
#利用生成的工具来处理输入的图片
tensor_img = tensor_trans(img)
print(tensor_img)
运行结果:
D:\Anaconda3\envs\unet\python.exe K:\code\learn_torch\read_data.py
tensor([[[0.3137, 0.3137, 0.3137, ..., 0.3176, 0.3098, 0.2980],
[0.3176, 0.3176, 0.3176, ..., 0.3176, 0.3098, 0.2980],
[0.3216, 0.3216, 0.3216, ..., 0.3137, 0.3098, 0.3020],
...,
[0.3412, 0.3412, 0.3373, ..., 0.1725, 0.3725, 0.3529],
[0.3412, 0.3412, 0.3373, ..., 0.3294, 0.3529, 0.3294],
[0.3412, 0.3412, 0.3373, ..., 0.3098, 0.3059, 0.3294]],
[[0.5922, 0.5922, 0.5922, ..., 0.5961, 0.5882, 0.5765],
[0.5961, 0.5961, 0.5961, ..., 0.5961, 0.5882, 0.5765],
[0.6000, 0.6000, 0.6000, ..., 0.5922, 0.5882, 0.5804],
...,
[0.6275, 0.6275, 0.6235, ..., 0.3608, 0.6196, 0.6157],
[0.6275, 0.6275, 0.6235, ..., 0.5765, 0.6275, 0.5961],
[0.6275, 0.6275, 0.6235, ..., 0.6275, 0.6235, 0.6314]],
[[0.9137, 0.9137, 0.9137, ..., 0.9176, 0.9098, 0.8980],
[0.9176, 0.9176, 0.9176, ..., 0.9176, 0.9098, 0.8980],
[0.9216, 0.9216, 0.9216, ..., 0.9137, 0.9098, 0.9020],
...,
[0.9294, 0.9294, 0.9255, ..., 0.5529, 0.9216, 0.8941],
[0.9294, 0.9294, 0.9255, ..., 0.8863, 1.0000, 0.9137],
[0.9294, 0.9294, 0.9255, ..., 0.9490, 0.9804, 0.9137]]])
除了用transforms中的ToTensor进行处理,也可以用opencv进行处理
pip install opencv-python
import cv2
cv_img = cv2.imread(img_path)
Transform的案例实现
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# 相对路径
img_path = "dataset/train/ants_image/0013035.jpg"
img = Image.open(img_path)
# 产生一个图形化的事件
write = SummaryWriter("logs")
# 使用transforms中的ToTensor函数生成一个工具
tensor_trans = transforms.ToTensor();
#利用生成的工具来处理输入的图片
tensor_img = tensor_trans(img)
# 将具有Tensor数字化信息的图片放到事件中去
write.add_image("Tensor",tensor_img)
write.close()
在命令行中执行tensorboard.exe --logdir=logs
(unet) PS K:\code\learn_torch> tensorboard.exe --logdir=logs
TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.19.0 at http://localhost:6006/ (Press CTRL+C to quit)
打开http://localhost:6006 展示出效果

对图片进行Normalize、resize、ToTensor等处理
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# 生成logs事件文件夹
write = SummaryWriter("logs")
# 读取普通的图片
img = Image.open("dataset/train/ants_image/6240329_72c01e663e.jpg")
# ToTensor实现,通过transforms工具生成一个新的totensor工具
trans_totensor = transforms.ToTensor()
# 用生成的这个totensor工具将普通图片转成有信息流的img_tensor图片
img_tensor = trans_totensor(img)
# 将生成的这个有信息流的img_tensor图片添加到logs事件中
write.add_image("ToTensor",img_tensor)
# Normalize实现,通过transforms工具生成一个新的tran_norm工具,
# 修改mean和std值,可以使图形有很大的变化;
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
# 把有信息流的img_tensor图片添加到tran_norm工具中生成变化后的img_norm图片
img_norm = trans_norm(img_tensor)
write.add_image("Normalize",img_norm,2)
# Resize 通过transforms工具生成一个新的trans_size工具
trans_size = transforms.Resize((512,512))
# 将普通的图片传给trans_size工具处理后生成img_resize图片
img_resize = trans_size(img)
# 再将这个变化大小后的图片img_resize经过trans_totensor处理成有信息流的img_resize
img_resize = trans_totensor(img_resize)
write.add_image("resize",img_resize,3)
write.close()
输出的效果展示。

Pytorch中的TorchVision中的数据集的使用
【1】、可以在PyCharm编译环境中通过代码直接下载到本地指定的文件夹中

【2】如果下载较慢或者无法下载,可以进入官网或上图所示的网址进行下载,下载以后是一个xxxx.tar.gz的包,
1、在项目的根目录下新建一个名为dataset的文件夹
2、将xxxx.tar.gz的包,放到dataset文件夹内;
3、执行一次以下代码就会自动校验并解压;
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# 因为没有从网上下载数据集,在参数download设成true以后会自动在当前项目中下到到dataset文件夹中
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
【3】对于有些下载数据集不显示网址,可以进入代码查看,在代码区按住ctrl不放点击数据集单词,进入数据集中向上找就能找到。

pytorchvision中数据集使用代码
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# 因为没有从网上下载数据集,在参数download设成true以后会自动在当前项目中下到到dataset文件夹中
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
# 打印测试数据集中的数据1是什么类型
# print(test_set[0])
# 打印测试数据集中有哪些类别
# print(test_set.classes)
#
# print(test_set.class_to_idx)
#
# print(test_set.url)
# # 同时获取数据据第一项的两个参数
# img,target = test_set[0]
# print(img)
# print(target)
# # 显示图片
# img.show()
#
writer = SummaryWriter("logs")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set",img,i)
writer.close()
在命令行中执行tensorboard.exe --logdir=logs就可以实现数据集的循环遍历了;
(unet) PS K:\code\dataset_transform> tensorboard.exe --logdir=logs
TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.19.0 at http://localhost:6006/ (Press CTRL+C to quit)
从Pytorch官网查询相关资料
dataloader参数可以从官网上查询
DataLoader的实现代码
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#准备的测试集
test_data = torchvision.datasets.CIFAR100("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=False,num_workers=0,drop_last=False)
# 测试数据集中第一张图片及target
img,target = test_data[0]
print(img.shape)
print(target)
# 产生一个事件,可用于显示图片的网页
writer = SummaryWriter("dataloader")
step = 0
# for data in test_loader:
# imgs,targets = data
# # print(imgs)
# # print(targets)
# writer.add_images("test_data",imgs,step)
# step = step + 1
for epoch in range(2):
step = 0
for data in test_loader:
imgs,targets = data
# print(imgs)
# print(targets)
writer.add_images("epoch{}".format(epoch),imgs,step)
step = step + 1
writer.close()
实现的展示效果
运行代码后在cmd命令行中执行tensorboard.exe --logdir=dataloader
