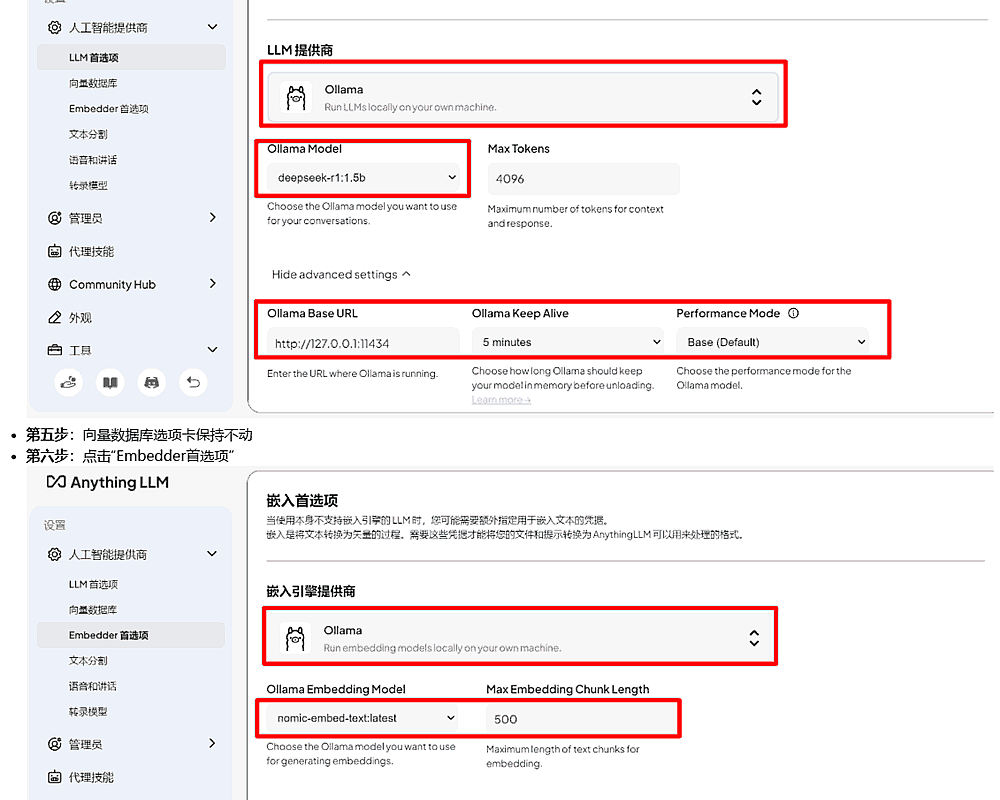
大模型本地部署和私有知识库

R1模型
模型设计:预训练、指令微调(SFT)、RLHF(人类强化学习的反馈)
后训练阶段(核心)强化学习
先部署一个小点的模型,7B就已经算是很大的了;

开源的模型,下载到本地部署,大部分场景都是不合适的。
开源的模型分类:
- 通用领域:【模型大】
- 细分领域:企业落地,7B左右模型,24GGPU*2,建议都是使用带有CUDA架构的显卡N卡
下载到本地部署。大部分场景都是不合适的
-根据需求来指定解决方案
-RAG【检索增强生成】,不需要对基础模型进行训练和微调
-fine-tuning【微调】拿着企业的私有化数据对基座模型进行微调训练-得到一个新的模型(垂直模型、行业模型、专业模型),要求有高质量的数据集,落地较困难;
查询电脑硬件是否符合要求,

RAG项目实战(使用 Llamalndex构建LIamaIndex构建企业私有知库)
1.使用Conda配置知识库项目Python环境
2.SentenceTransformer大模型详解
3.Embedding文本向量化处理实战
4.InternLM2.5-1.8B/Qwen2.5-0.5B模型实战
5.知识库模型问答测试与实际效果评估
6.使用LLamalndex创建知识库实战
7.使用Streamlit创建Web应用实战
1.环境配置,使用Conda配置项目的Python环境
#创建环境
conda create -n llamaindex-ragpython=3.10
#激活环境
conda activate llamaindex-rag
#安装项目所需的依赖库(requirements.txt在项目代码包中)
pip install -r requirements.txt
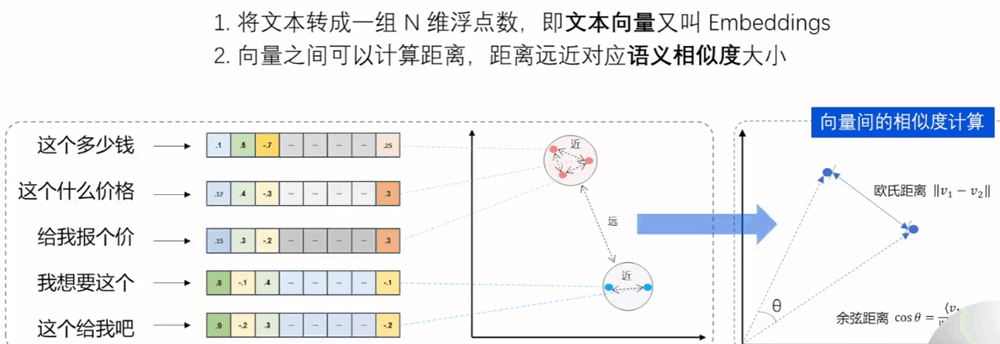
每一个向量对应一原始数据【即文档中的内容】,然后根据查询的提示词打包输出给生成式模型LLM。

将文档分割成块

文本向量的定义,语义相似度的概念
示例
prompt_template = “”
你是一个问答机器人,
你的任务是根据下述给定的已知信息回答用户问题。
已知信息:
{context} #[context}就是检索出来的文档
用户问:
{question} #[question就是用户的问题
如果已知信息不包含用户问题的答案,或者已知信息不足以回答用户的问题,请直接回复”我无法回答您的问题”请不要输出已知信息中不包含的信息或答案。
请用中文回答用户问题
“”
下载Sentence Transformer模型【文本向量模型】,注:模型的下载都在modelscope
#模型下载
from modelscope import snapshot_download
#modelid模型的id
#cachedir缓存到本地的路径
model_dir=snapshot_download(model_id=”Ceceliachenen/paraphrase-multilingual-MiniLM-L12-v2,cache_dir=”D:/AIProject”)

下载推理模型,可以是DeepSeek-R1,Qwen-1.5B;
#模型下载
from modelscope import snapshot_download
#modelid模型的id
#cachedir缓存到本地的路径
model_dir=snapshot_download(model_id=”Qwen/Qwen2.5-0.5B-nstruct,cache_dir=”D:/AIProject”)

调用本地模型进行推理测试
执行下面代码进行提问测试,可以看出模型本身不具备关于xtuner的相关知识,回复也比较乱。
from llama_index.Lms.huggingface import HuggingFaceLLM
from llamaindex.core.ilms import ChatMessage
#使用HuggingFace加载本地大模型
llm=HuggingFaceLLMo(
#给定的是本地模型的全路径
model_name=r”D:lAIProject|modelscopelQwenlQwen2_-_5-0_-_5B-Instruct”,
tokenizer_name=r”D:\AIProject\modelscope\QwenlQwen2_-_5-0_-_5B-Instruct” ,
model_kwargs={“trust_remote_code”:True},
tokenizer_kwargs=f”trust_remote_code”:True},
device_map=Auto #如果有GPU会在显卡上跑,如果没有会在CPU上跑
)
rsp=llm.chat(messages=[ChatMessage(content=”xtuner是什么?”])
print(rsp)