
SD图像生成及图片处理(一)

Stable Diffusion出图原理
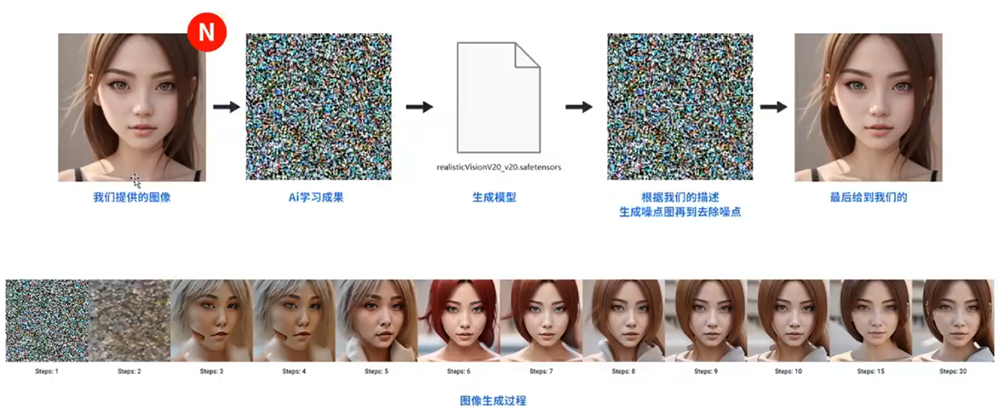
AI 是怎样生成图片的,通过喂很多的图片,它记忆的是很多的噪点,,生成一个模型,再根据我们的描述生成噪点图再到去噪点,最后给我们图片。
Stable Diffusion与模型之间的关系
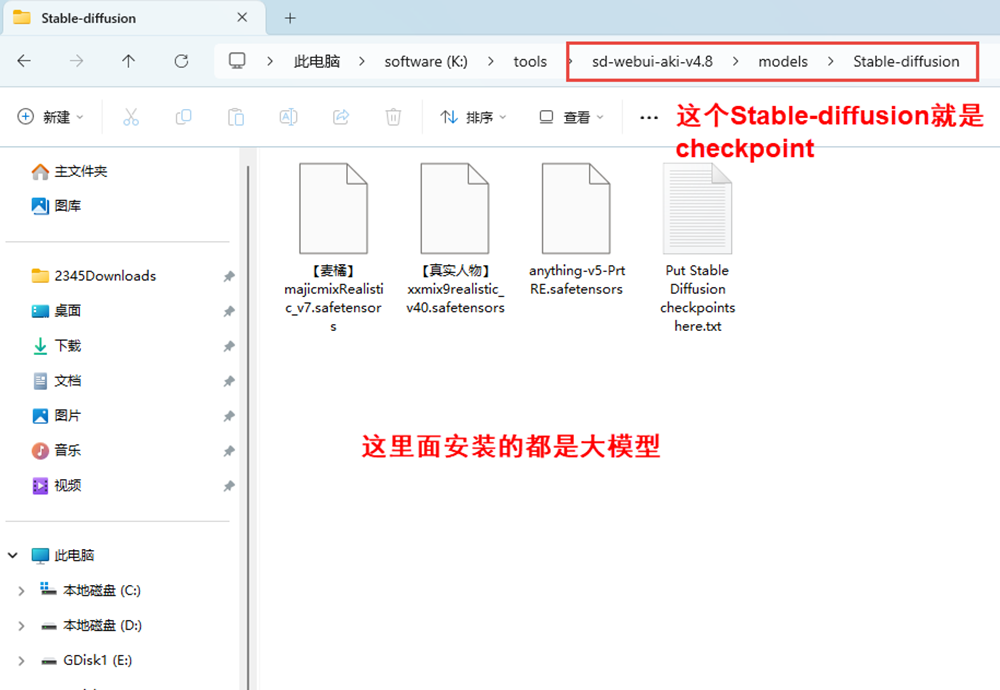
Checkpoint(检查点/大模型)
之所以称之为大模型,是因为checkpoint模型在训练之初所存储的学习信息量比起其它模型来说要多的多,由于训练大模型需要更多的数据集,所以很消耗算力,所以在运算到某个关键位置的时候就会建立一个关键点,用来保存已经运算的部分,后续方便回滚和继续计算。这就是checkpoint的来源。
这里面安装的都是大模型,下载的大模型放在这个路径下就可以了。stable-diffusion就是checkpoint
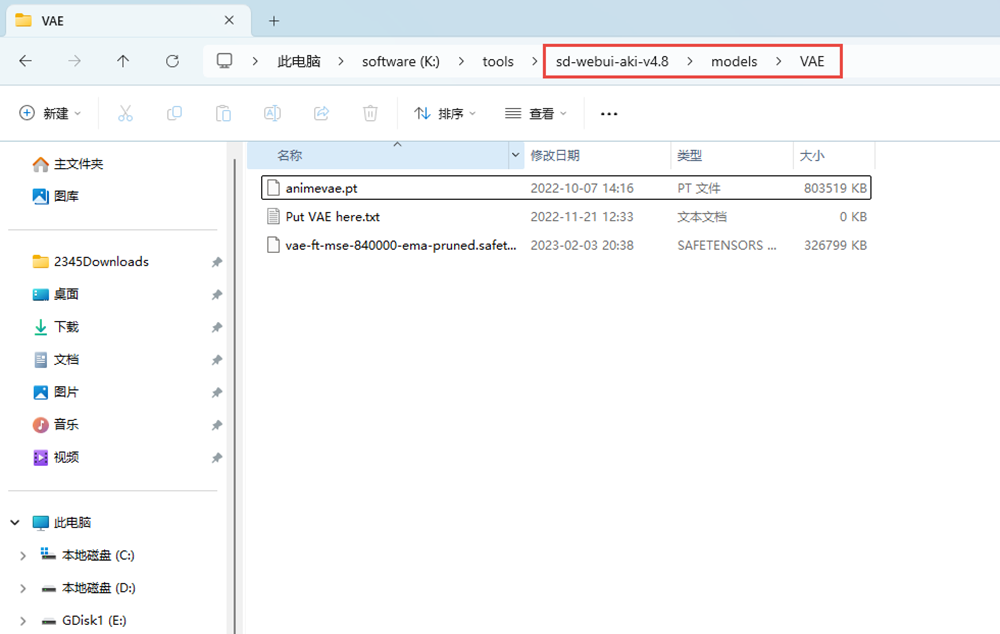
VAE:Variational Auto Encoder(变分自解码器)
VAE是负责将加噪后的潜空间数据转化为正常的图像,如果不好理解的话可以简单的将VAE理解为Ai绘图的一种“调色滤镜”主要影像画面的色彩质感
因为VAE最直观的影响的就是画面的色彩质感,不过目前很多的大模型中已经将VAE整合进了大模型文件当中了,所以有的时候你会发现不添加VAE的情况下出来的效果也是不错的。
也有一些模型没有将VAE整合到大模型中,所以出来的图像就会发灰发白。所以如果遇到以上情况我们要检查是否打开了VAE。VAE所在路径K:\tools\sd-webui-aki-v4.8\models\VAE
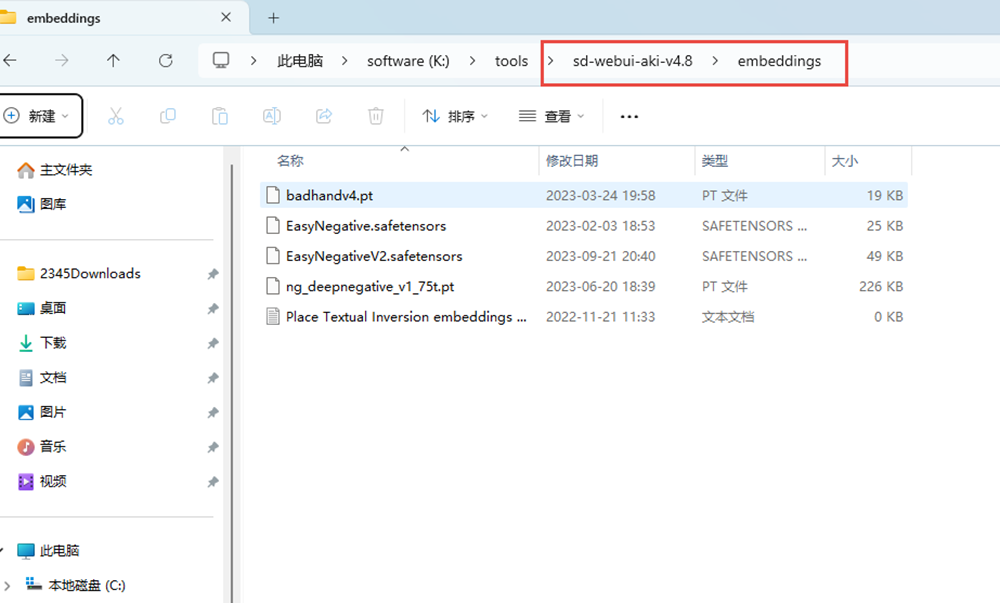
Embeddings:文本嵌入(深度学习中:嵌入式向量)
Embeddings:优化画风所以用的微小型模型,这也是它的精髓所在,如果将checkpoint比作一本大词典,那么它就相当于小书签,它可以精准的指向某个字、词的含义。从而提供一个非常高效的索引。这种索引方式除了可以帮助SD绘画好已经有的东西以外,有时候也可以帮我们实现特定形象的呈现。
这个模型可以嵌入到我们的prompt当中使用,可以描述对象或者概念,也可以添加到负面词消除错误的手(在这里并不能完全给到我们一双完美的手)只是在一定程度上消除错误的手。
这个模型在C站筛选模型中的名称叫做:TextureInverson“文本倒置”
LoRa:Low-RankAdaptationModels(低秩模型)
LoRa:它的作用在于帮助我们向Ai传递、描述某一个特征准确,主体清晰的形象。举个例子:咱们让ai帮我们画一个哥,好这个时候SD的大脑中没有磊哥的数据,那这个时候怎么办?ai东拼西凑也不出来呀,能画出来也长得不是我这个样学
回到上面的例子我们将Embeddings举例为小书签,那么LoRa就相当于一个贴在学典中的备忘贴纸,上面明确的写清楚了磊哥多高,五官什么样,发型什么样,有什么特点,可以用什么方式呈现出来。这样A对“磊哥”这个词理解的就更加全面精准。
所以想一定程度上还原一个人我们就要对这个人进行“模型训练”俗称:炼丹
Hypernetwork:超网络
Hypernetwork:虽然在作用原理上有所差异,但超网络最后能实现的效果其实和LoRa是差不太多的,也可以通过它让Ai学习一些在它“脑子”中不存在的东西吗,并且描述清楚一步到位。
说LoRa是备忘贴纸,那么它可以算作小卡片,都差不多。唯一的区别就是Hypernetwork一般用于改善生成图像的整体风格。也就是我们所谓的“画风”但是这个画风比checkpoint所定义的画风要更为精细一些,不像二次元和写实之间的那种区别,倒是想梵高与莫奈之间的区别!
以前版本添加Lora和Hypernetwork方法,在设置—–扩展里面。
Stable Diffusion模型如何下载
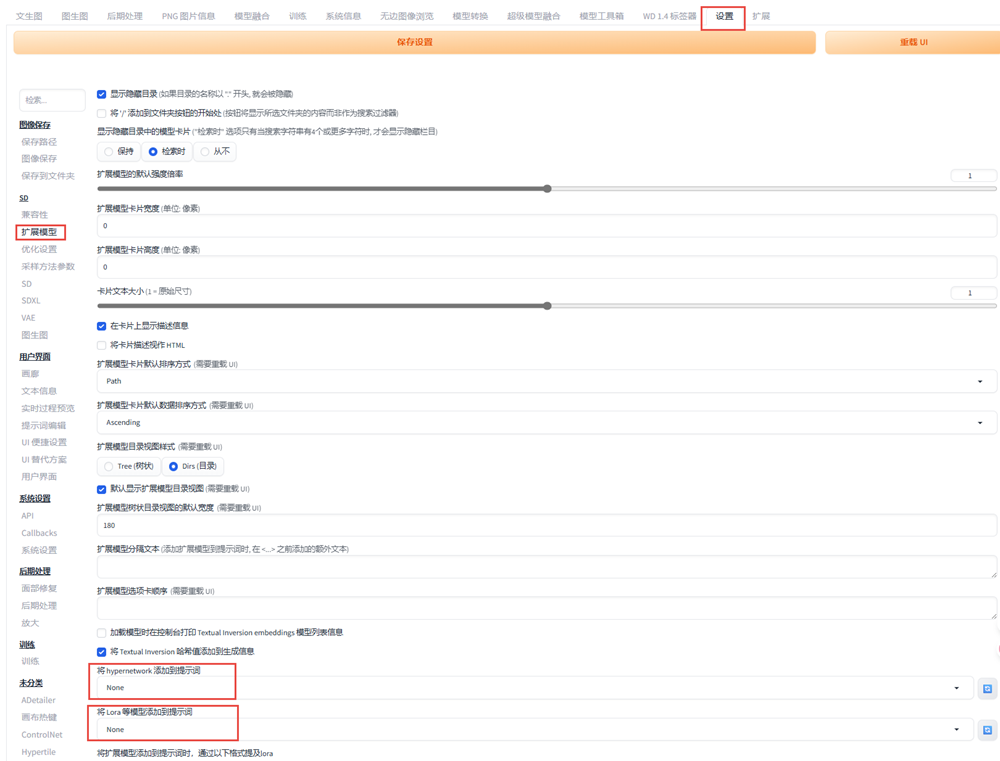
从可以从civitai官网下载模型,需要魔化才可以打开此网站。打开concept Head-mounted display – v1.0 | Stable Diffusion LoRA | Civitai网站,先复制这张大图;
下载的模型和预预图片名称一致,也就是将图片的名称改成跟模型名称一样,
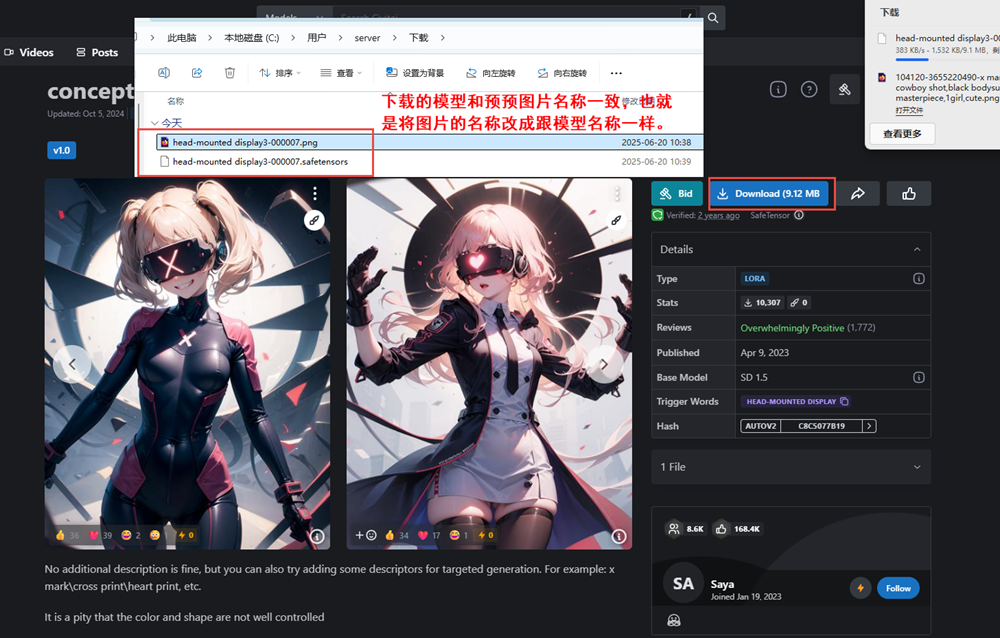
在K:\tools\sd-webui-aki-v4.8\models\Lora\路径下新建一个头带VR眼镜文件夹,将改完名称的两个文件拷贝进去。
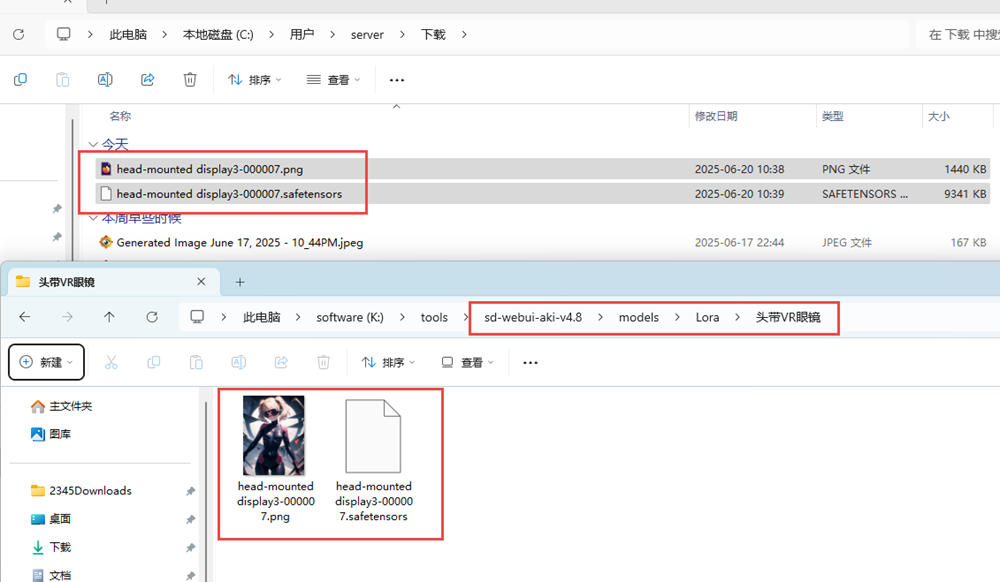
将图片拖到PNG图片信息中查看提示词,然后发送到文生图;
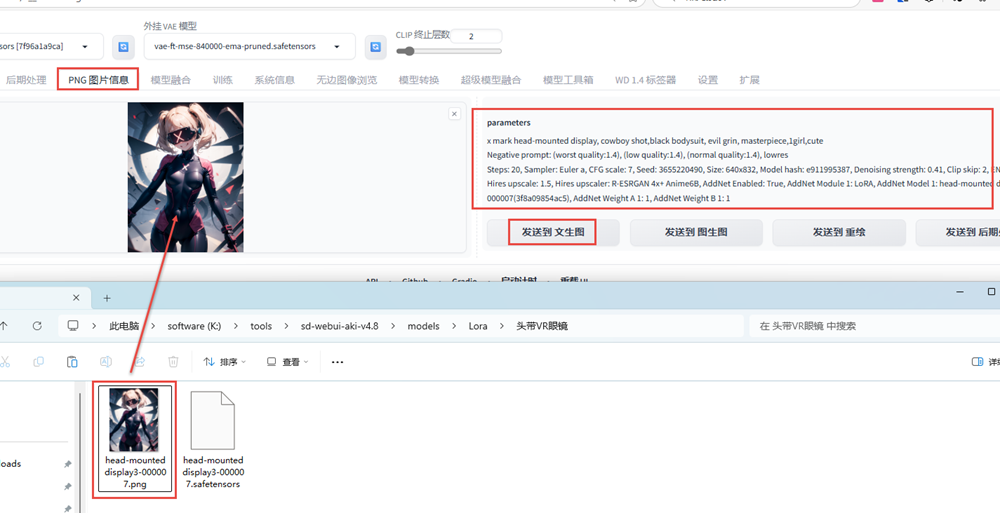
也可以在官网上打开这个图片,查看提示词。
正向提示词 x mark head-mounted display, cowboy shot,black bodysuit, evil grin, masterpiece,1girl,cute
反向提示词 (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowres
Stable Diffusion中Clip跳过层是什么意思
Clip就是语言与图像的对比预训练
覆盖设置:就是你上一次出这张图的时候,存储这个生成的图片的时候,它会把你设置这个内容给它全部加上去;
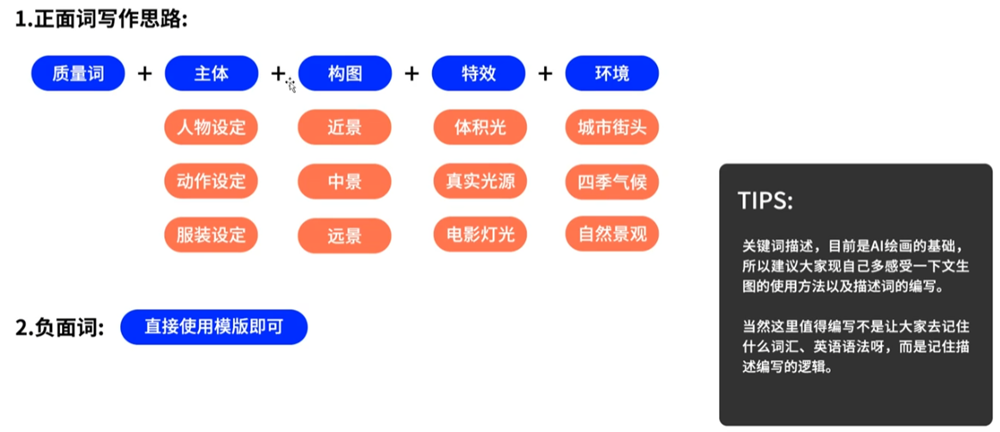
Prompt提示词的基本写作思路
正面词就是要生成的图的描述,负面词就是你不想要的描述;关键词可以从这个网站查询
Masterpiece,top quality,best quality,official art,8k,purple and white patterned dress with white ribbon tied at the waist and emeralds on the ribbon,solo,short sleeves,dress,wide sleeves,short white dress,pretty girl,shows full body,blue sky background,
<lora:head-mounted display3-000007:0.8>,
负面词
multiple breasts, {mutated hands and fingers:1.5}, {long body :1.3}, {mutation, poorly drawn :1.2} , black-white, {{bad anatomy}}, liquid body, liquid tongue, {{disfigured}}, malformed, mutated, anatomical nonsense, text font ui, error, malformed hands, faeces, shit, futa,, panties, thong, fundoshi,
Prompt文案提示词的基础语法

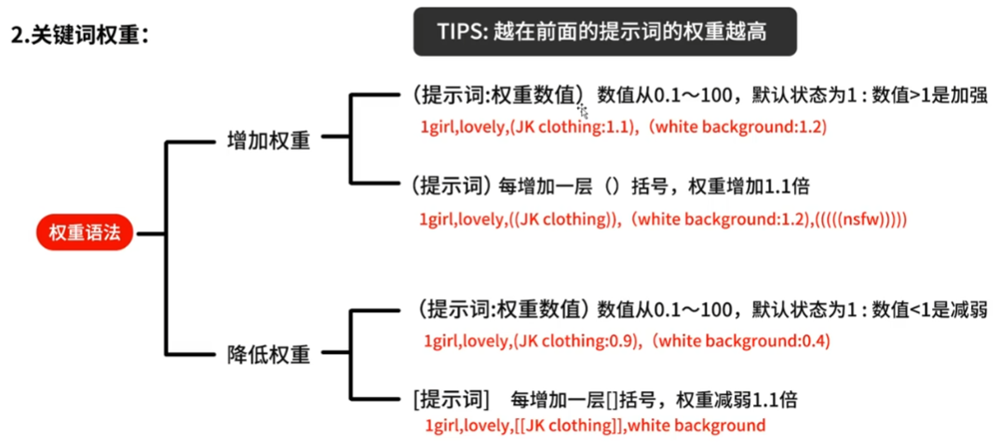

[dog:rabbit:20] 前20步生成狗,其余的步数生成兔子
[dog:rabbit:0.6] 前60%生成狗,后40%生成兔子
[dog:rabbit],[to:20] 前面的步数画狗,后20步画兔子
[dog::20],[from::10] 前20步画狗,后10步停止绘画
[dog::0.4],[from::0.6] 前40%步画狗,后60%步停止绘画


[dog::20],[from::10] 前20步画狗,后10步停止绘画
[dog::0.4],[from::0.6] 前40%步画狗,后60%步停止绘画

根据目前的几个算法测试DPM2 a与DPM++2S a Karras可以用改命令,也就是采样方法选择上面的两种才可以。

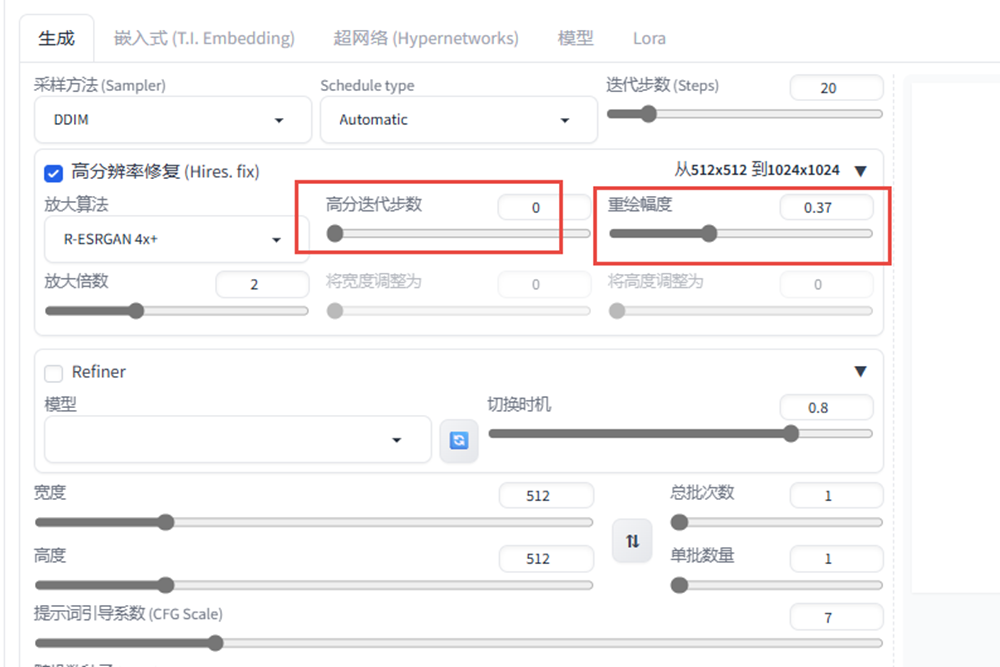
迭代步数(Steps)
首先我们要知道:StableDiffusion是一个用于图像处理的算法,用于图像去噪和增强。
在该算法中,选代步数(Steps)是指算法选代更新图像的次数。每一次选代,算法会更新图像的像素值,直到达到预设的选代步数为止。选代步数越多,算法对图像的处理就会更加充分,但也会增加算法的计算时间和计算复杂度。因此,在实际应用中,需要根据具体情况来选择合适的送代步数,以充分处理图像的同时,尽可能减少计算成本。
- 采样方法如果选择DPM adaptive那么迭代步数也就不起作用了。当不知道设多少步时,可以使用,比较吃硬件资源;

对于不需要的采样器可以进入设置—–采样方法参数中,将不用的勾选并隐藏掉就可以了。
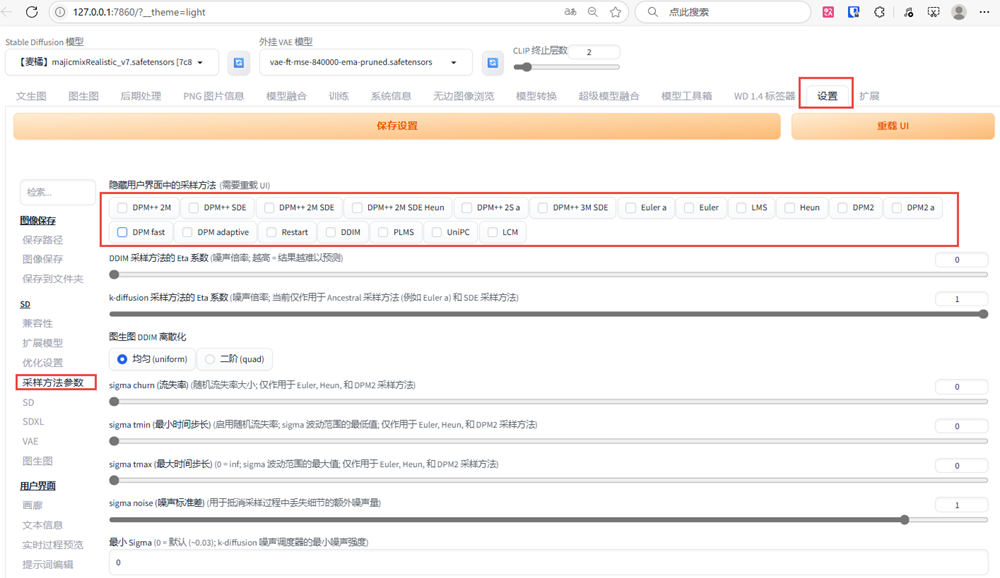
面部修复, 二次元风格不适用于面部修复。

高清修复可以实现小图变大图的功能

高分迭代步数不能设很高,重绘幅度如果值较大与之前的图像差别就会很大;
如果宽高比超过AI记忆中的尺寸,那么就会出现一些很鬼畜的画面。

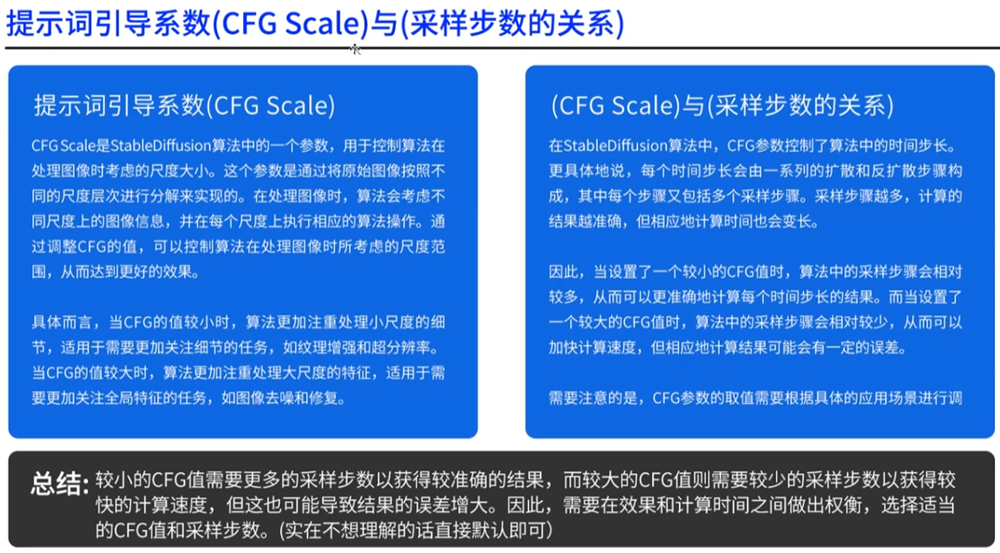
提示词引导系数CFG Scale与采样步数的关系
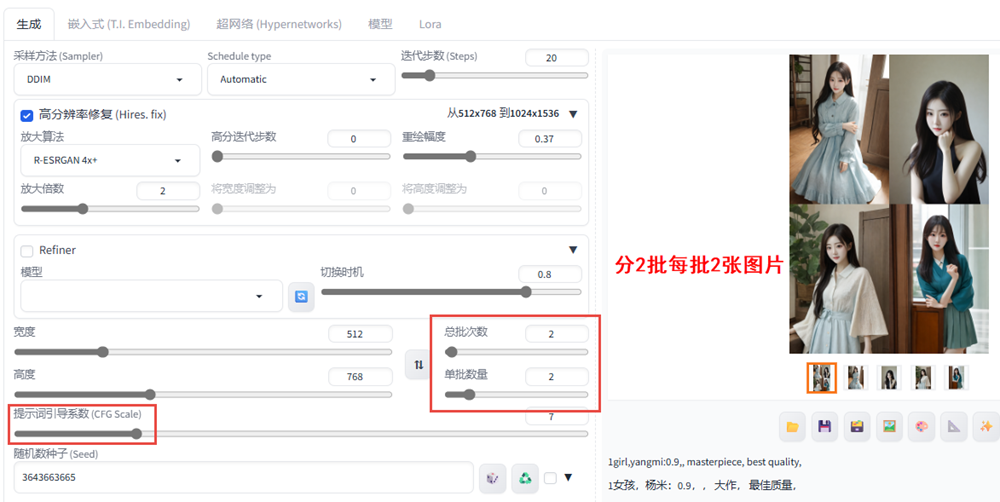
总批次数与单批数量的概念
随机种子
随机种子是模型生成图片的起点。在SD中,输入一个随机种子,模型会基于这个种子生成一张图片。每次输入相同的随机种子,会生成完全相同的图片。
随机种子给模型一个确定的起点,产生可控且可重复的生成结果。这在许多应用中很有用,比如说你找到一个你喜欢的生成结果想再产生类似的图片,就可以使用相同的随机种子。
随机种子产生确定的生成经果,变异随机种子基于此作品,作出小幅变化,实现连续变化的效果。随机种子控制生成,变异随机种子实现变化,,两者一起使用可以产生一系列相关但又不完全相同的生成结果。
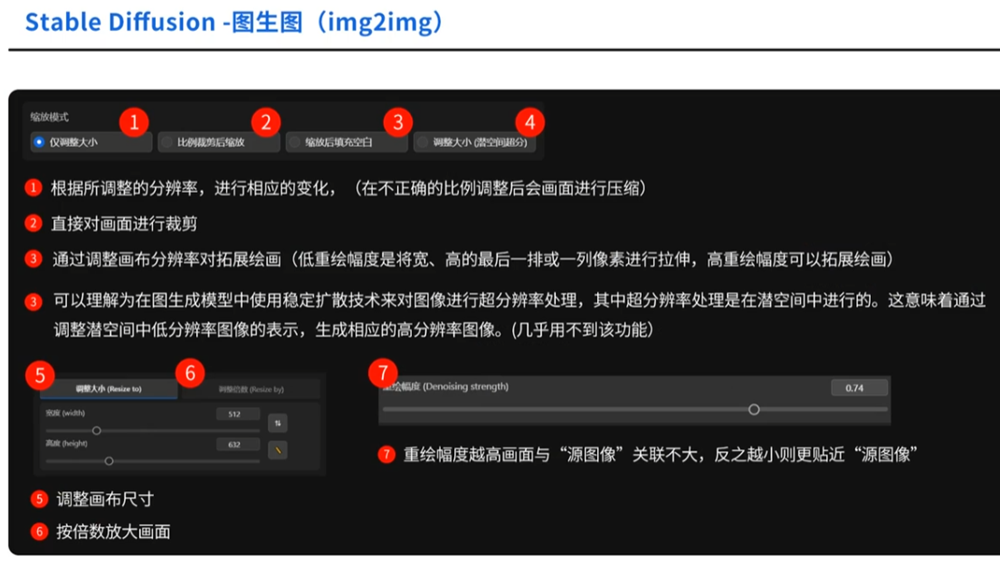
图生图
图生图(img2img)
基本原理是使用扩散过程逐渐将源图像转化为目标图像。该过程在多个步骤中进行,每个步骤中,图像会被扩散(模糊),然后经过改进以逐渐接近目标图像。扩散步骤允许探索多样化的变化,并为生成的图像添加随机性。
有3种方法:1、是CLIP反推,文本与图像的关系模型;2、DeepBooru反推,征对绘画和动漫;3、WD1.4标签器(Tragger)
可以去花瓣官网下载
图生图的使用场景,手绘稿的优化,图像风格转化,根据源图片延展新效果。

1、重绘的值不能调的太高,否则的话变化太大,
2、选择相应的模型,不同的模型效果方向不同。
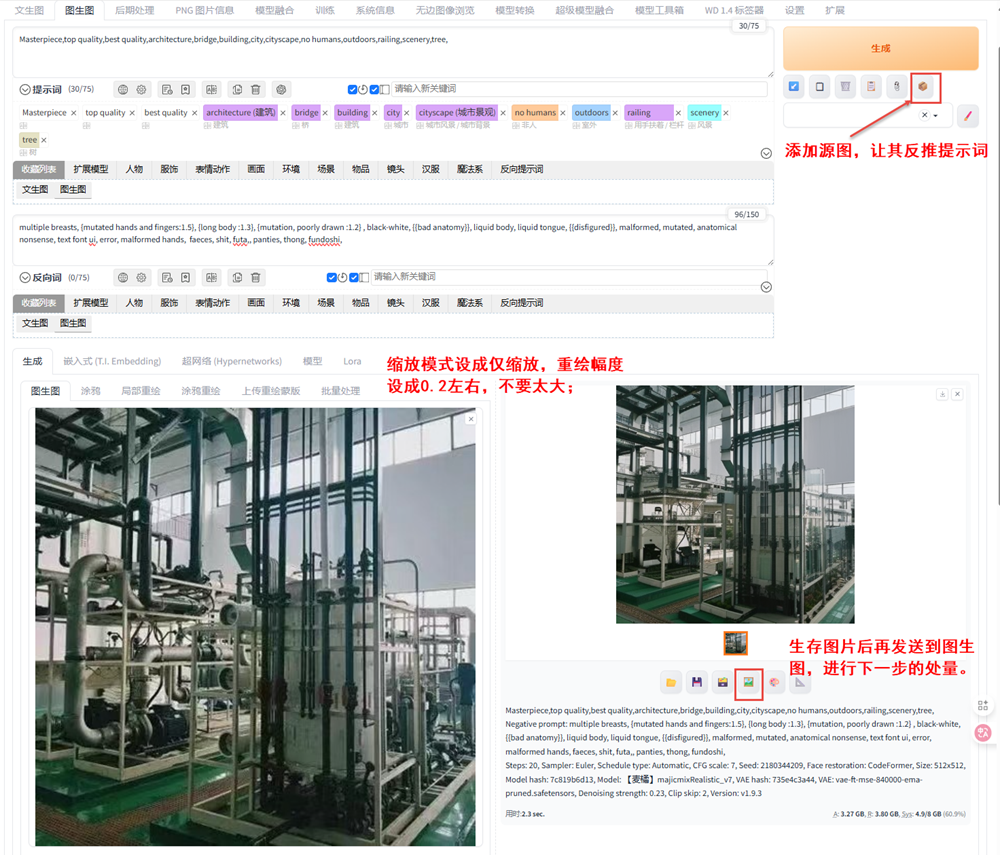
3、加载源图,点按钮生成反推提示词,再添加上一些修饰提示和反提示词
4、对于图生图的原图如果尺寸不合适可以裁剪一下,缩放模式设成仅缩放,重绘幅度设成0.2左右,不要太大;【起初可以将重绘改成0让其,同步一下大小】
5、将生成的图片再次发送到图生图,让其循环处理,还可以修改大模型来处理;
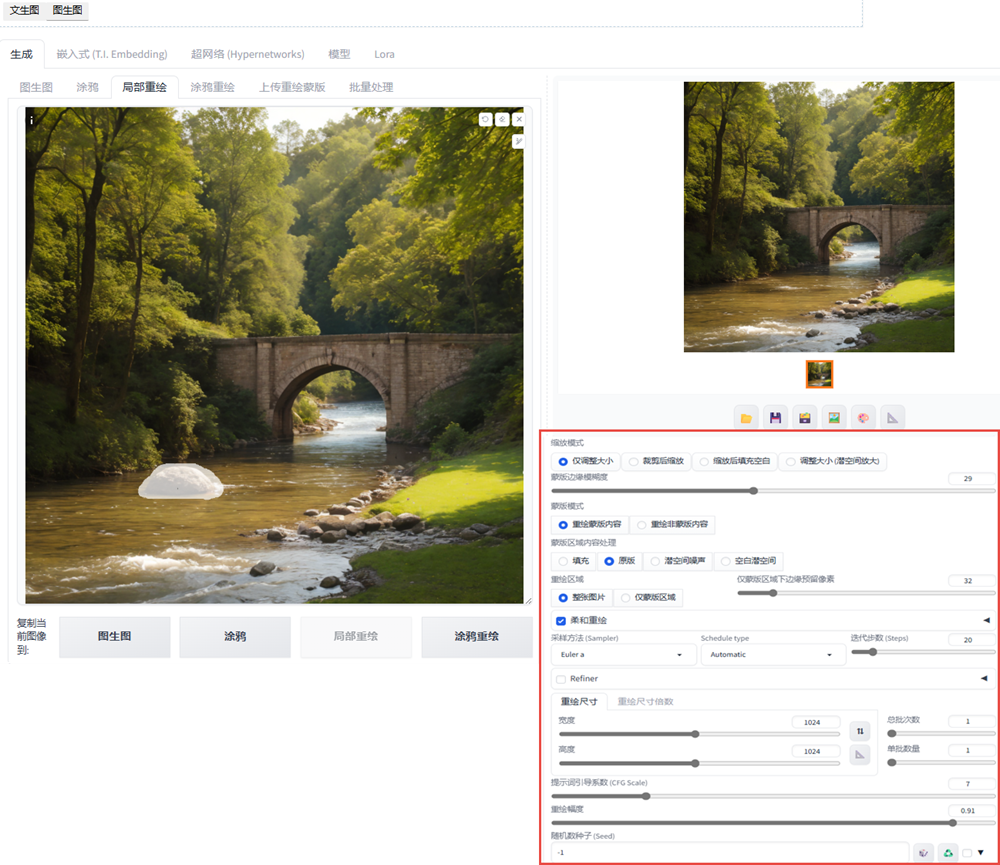
图生图的局部重绘

涂鸦是整张图全部重绘,局部重绘蒙板的使用,重绘蒙板内容,重绘区域选整张图片,柔和重绘,重绘幅度加大。
可以对加载的图片进行图生图处理,在图生图中选择局部重绘,调整蒙板和采样方式,以及对重绘幅度进行调整,再加上对提示词的输入,然后在源图上进行涂抹蒙板就可以生成变脸、变物了。如下图所示:对其进行了项链和束腰的处理。

涂鸦重绘,是涂鸦与局部重绘相结合进行局部重绘形式算法

上传蒙板
在这个功能中,系统默认是白色为蒙板,黑色为非蒙板;如果在实验时分发现自定义画面还是用白色背景的底图时,都会出现多个人、或者人物有重叠之类的现象,如果以上情况我们应先查看,模型、底图、分辨率、关键词。注:更换背景的时候,不要选择"蒙板区域内容处理"。

步骤:新建一个白色背景;
2、钢笔PS抠图,然后填充成白色;
3、再加上蒙板将胳膊图出来。
4、再将背景填充成黑色;


注:换背景时选择填充,重绘非蒙板区