
基于VLLM本地部署DeepSeek模型

什么是VLLM
如果是在企业里有一定规模的话一般都有VLLM来部署大模型,它是一个高效的大语言模型框架。它具有高效的推理和部署服务系统;
高效的内存管理:通过PagedAttention算法,vLLM实现了对KV缓存的高效管理,减少了内存浪费,优化了模型的运行效率。
易用性:vLLM与HuggingFace模型无缝集成,支持多种流行的大型语言模型,简化了模型部署和推理的过程。兼容openAl的API服务器。
分布式推理:框架支持在多GPU环境中进行分布式推理,通过模型并行策略和高效的数据通信,提升了处理大型模型的能力。
开源共享:VLLM由于其开源的属性,拥有活跃的社区支持,这也便于开发者贡献和改进,共同推动技术发展。
高吞吐量:VLLM支持异步处理和连续批处理请求,显著提高了模型推理的吞吐量,加速了文本生成和处理速度。
本例演示环境说明
操作系统:
Ubuntu24.0
GPU:NAVIDIAA10显卡``24GB显存
CPU:16Core VLLM: 0.7.x
Python:3.10
NVIDIA驱动:12.4 CUDA:12.4
注:vllm只支持Linux环境,而且必须要有GPU资源。
安装annoconda
1、创建一个目录名为miniconda3
2、下载miniconda3的linux版的脚本到新建的目录中。

3、然后执行这个脚本,至此,miniconda3工具就已经安装完毕了。
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3 PREFIX=/root/miniconda3
4、执行source /root/.bashrc使miniconda3生效;
5、更换conda的源 vim /root/miniconda3/.condarc

6、针对vLLM创建一个环境:conda create --name vLLM python=3.10 -y
安装NVIDIA的驱动
1、安装依赖包
apt install -y build-essential dkms
2、去nvidia官网下载驱动,下载好以后上传到服务器。

3、在服务器上执行安装nvidia显卡驱动 dpkg -i nvidia-driver-local-repo-ubuntu2024-xxxxx.deb
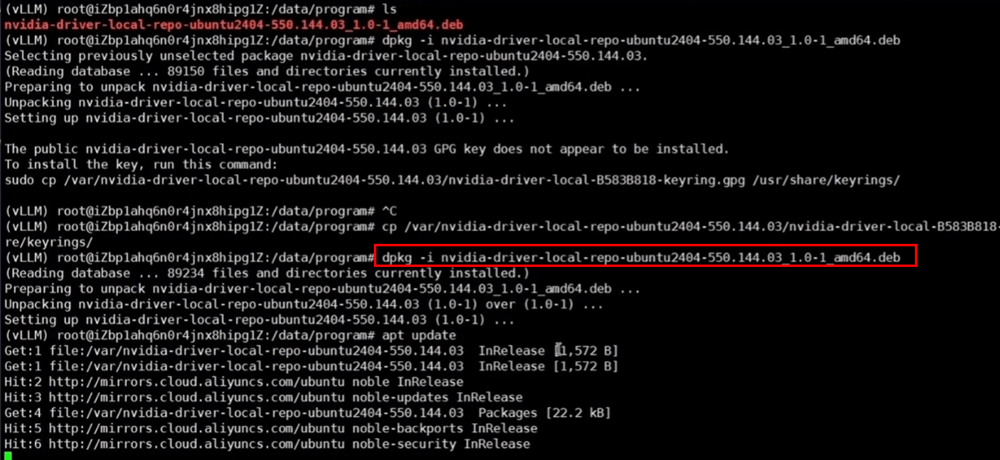
4、安装cuda驱动 apt install -y cuda-drivers
5、安装cuda toolkit工具包,官网有安装说明;

安装完以后设置环境变量,这样在任何地方都可以执行了。不用每次执行都要切换到特定的地方。

6、pytorch的下载和安装。pip install torch-2.4.0+cu124-cp310-linux_x86_64.whl
7、pip install vLLM

模型的下载
